

How Snowflake Revolutionizes Data Warehousing
To overcome these technical challenges, Snowflake creators had to shift certain paradigms.
The most important shift was to plan Snowflake exclusively for the cloud. So, contrary to nearly every other solution that existed back then, users could not install Snowflake locally on their own servers.
This decision enabled the creators to make a series of choices that would have been extremely hard, if not impossible, otherwise.
Since most of them are quite tech heavy, I’m going to stick to the library metaphor and avoid technical mumbo-jumbo.
In brief:
- Storage is organized by having both the big library as well as the portable bookshelf for each librarian.
- Librarians keep only the most requested books on their shelves, and they are “on call”.
- The library has “translators”, so they can catalog books written in other languages immediately when they’re stored.

The architectures we previously discussed (shared-storage and shared-nothing) have some merits which should not be overlooked. Instead of reinventing the wheel, Snowflake’s approach is a mix of both.
For starters, it keeps the shared-storage, aka the big library building. In fact, the founders went a step further and recognized that it wasn’t even worth building one themselves, as they could take advantage of existing cloud solutions (AWS S3, for instance) that fit the bill perfectly.
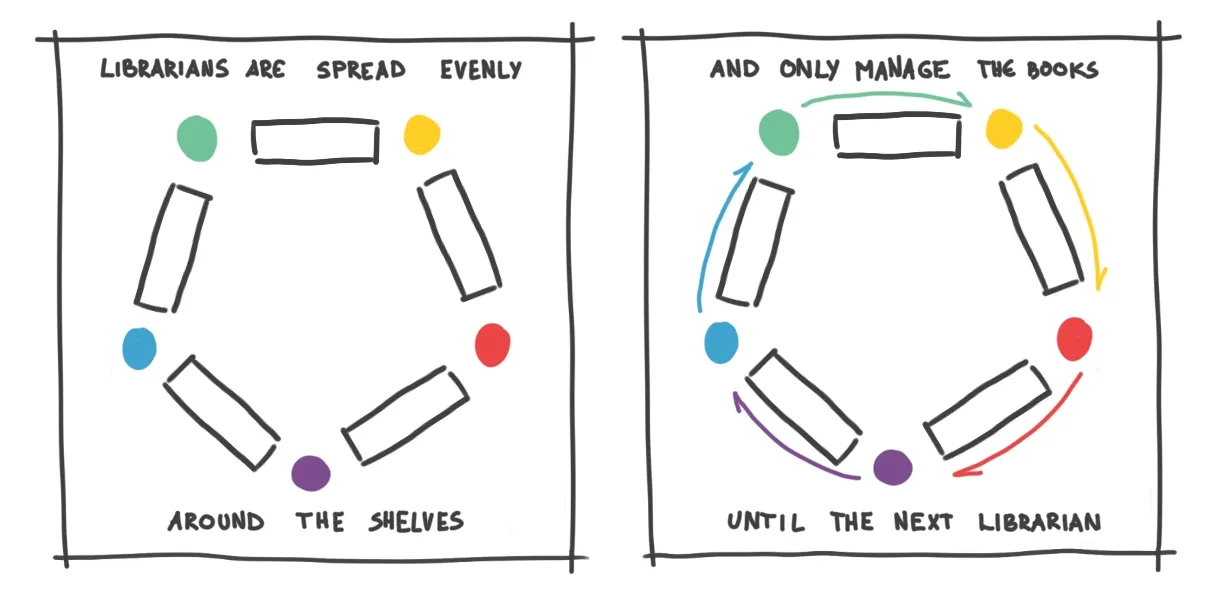
Librarians also have their own portable bookshelf, where they store copies of only the most requested books. This way, they have to check the big library only when they don’t have a book readily available.

Lastly, librarians are "on call," coming online only when a request is received. After handling the request, they wait briefly for any additional queries and then go offline if none arrive.
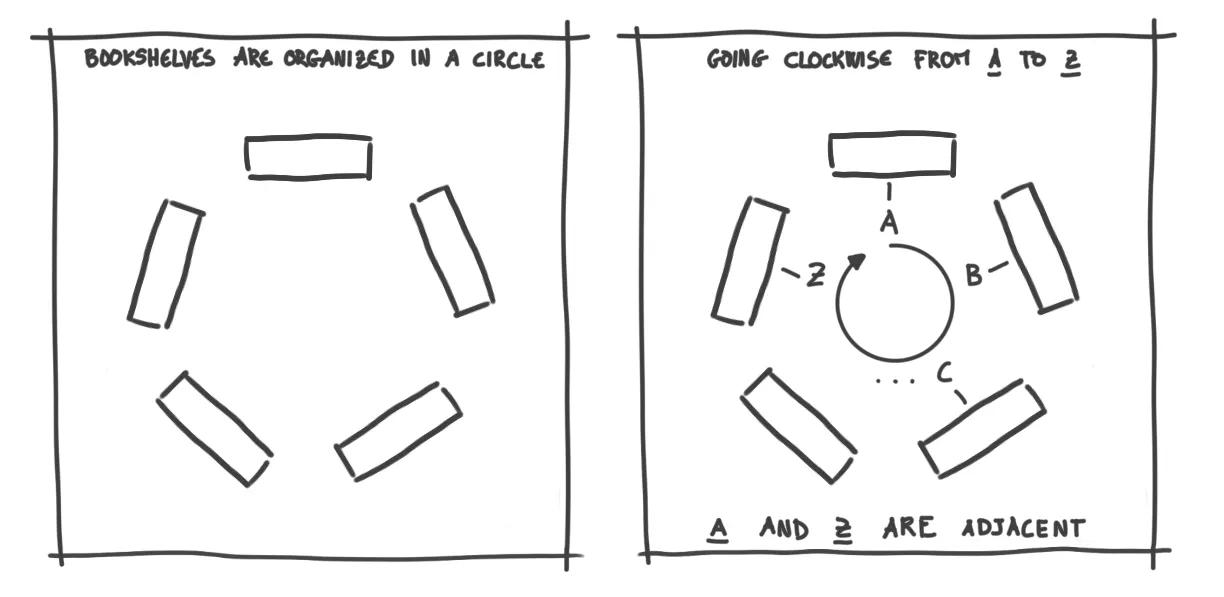
This solves the issue of speed and scaling, but what about organizing the books? How do librarians know which books are assigned to them?
The answer is an algorithm called consistent hashing. It sounds complicated, but it’s actually quite intuitive.
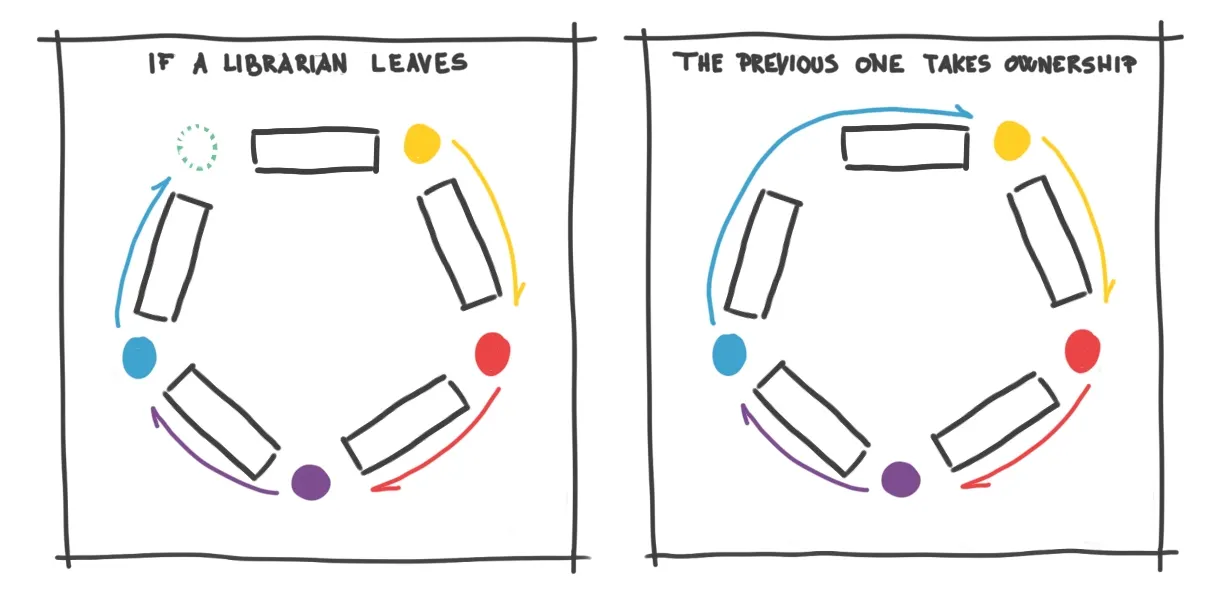
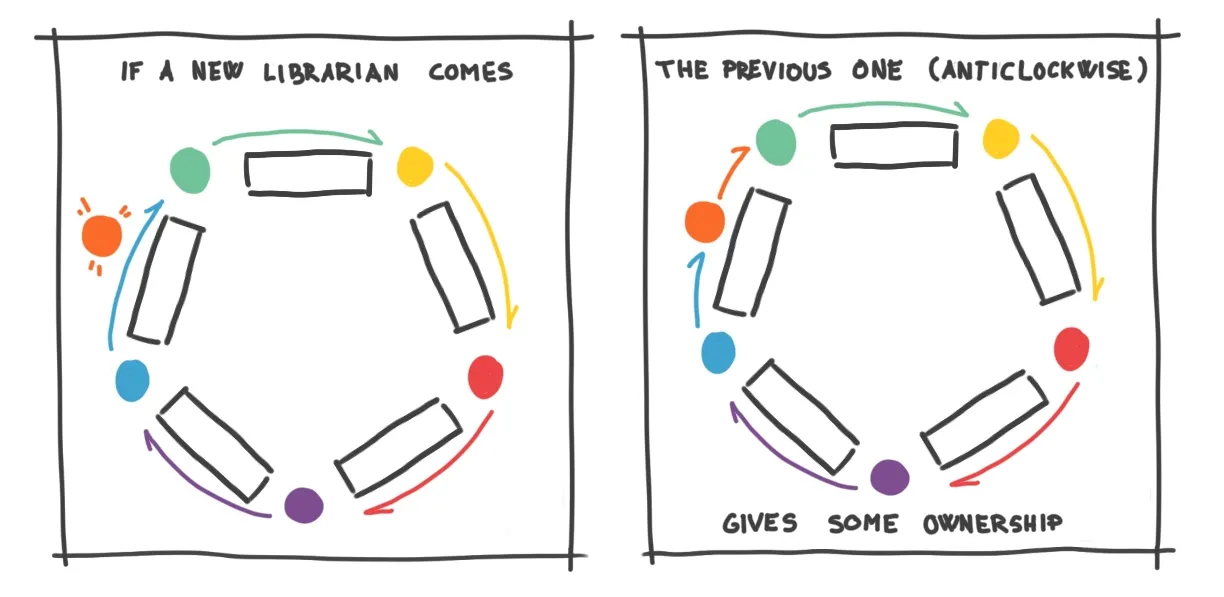
This increases flexibility and speed, avoiding a total reshuffle when numbers change, and ensuring continuous availability for answering questions.
The remaining problem is handling unstructured vs. structured data (i.e. French vs. English books). Like we covered earlier, many systems couldn't store unstructured data, and those that could required a lot of extra work.
Snowflake’s approach to solve this issue consists of three steps:
- It allows the customer to store any kind of book, with no extra work on their side
- In the backlines, it implements “translators”, which translate and catalog these books for easy retrieval of information later on.
- The original copy of the book is also kept, in the odd chance that the translators made a mistake and it needs to be fixed.

This way, customers can easily store and retrieve any kind of data (structured and non structured), without any of the extra work required by previous systems.
How does the final user benefit from all these changes and improvements? Let’s see it in the next chapter.


How Snowflake Revolutionizes Data Warehousing
To overcome these technical challenges, Snowflake creators had to shift certain paradigms.
The most important shift was to plan Snowflake exclusively for the cloud. So, contrary to nearly every other solution that existed back then, users could not install Snowflake locally on their own servers.
This decision enabled the creators to make a series of choices that would have been extremely hard, if not impossible, otherwise.
Since most of them are quite tech heavy, I’m going to stick to the library metaphor and avoid technical mumbo-jumbo.
In brief:
- Storage is organized by having both the big library as well as the portable bookshelf for each librarian.
- Librarians keep only the most requested books on their shelves, and they are “on call”.
- The library has “translators”, so they can catalog books written in other languages immediately when they’re stored.

The architectures we previously discussed (shared-storage and shared-nothing) have some merits which should not be overlooked. Instead of reinventing the wheel, Snowflake’s approach is a mix of both.
For starters, it keeps the shared-storage, aka the big library building. In fact, the founders went a step further and recognized that it wasn’t even worth building one themselves, as they could take advantage of existing cloud solutions (AWS S3, for instance) that fit the bill perfectly.
Librarians also have their own portable bookshelf, where they store copies of only the most requested books. This way, they have to check the big library only when they don’t have a book readily available.
Lastly, librarians are "on call," coming online only when a request is received. After handling the request, they wait briefly for any additional queries and then go offline if none arrive.
This solves the issue of speed and scaling, but what about organizing the books? How do librarians know which books are assigned to them?
The answer is an algorithm called consistent hashing. It sounds complicated, but it’s actually quite intuitive.
This increases flexibility and speed, avoiding a total reshuffle when numbers change, and ensuring continuous availability for answering questions.
The remaining problem is handling unstructured vs. structured data (i.e. French vs. English books). Like we covered earlier, many systems couldn't store unstructured data, and those that could required a lot of extra work.
Snowflake’s approach to solve this issue consists of three steps:
- It allows the customer to store any kind of book, with no extra work on their side
- In the backlines, it implements “translators”, which translate and catalog these books for easy retrieval of information later on.
- The original copy of the book is also kept, in the odd chance that the translators made a mistake and it needs to be fixed.
This way, customers can easily store and retrieve any kind of data (structured and non structured), without any of the extra work required by previous systems.
How does the final user benefit from all these changes and improvements? Let’s see it in the next chapter.
Chapters

Chapters
How Snowflake Works: Intro
Understanding Data Warehousing
Limits of Past Solutions

How It Revolutionize Data Warehousing?
How It Benefit Users: Wrapping Up
Cortex AI
New
What is Cortex AI?
The Case for AI in the Data Warehouse
An Overview of Cortex AI
LLM Functions
Snowflake Copilot
How Snowflake Revolutionizes Data Warehousing
To overcome these technical challenges, Snowflake creators had to shift certain paradigms.
The most important shift was to plan Snowflake exclusively for the cloud. So, contrary to nearly every other solution that existed back then, users could not install Snowflake locally on their own servers.
This decision enabled the creators to make a series of choices that would have been extremely hard, if not impossible, otherwise.
Since most of them are quite tech heavy, I’m going to stick to the library metaphor and avoid technical mumbo-jumbo.
In brief:
- Storage is organized by having both the big library as well as the portable bookshelf for each librarian.
- Librarians keep only the most requested books on their shelves, and they are “on call”.
- The library has “translators”, so they can catalog books written in other languages immediately when they’re stored.
The architectures we previously discussed (shared-storage and shared-nothing) have some merits which should not be overlooked. Instead of reinventing the wheel, Snowflake’s approach is a mix of both.
For starters, it keeps the shared-storage, aka the big library building. In fact, the founders went a step further and recognized that it wasn’t even worth building one themselves, as they could take advantage of existing cloud solutions (AWS S3, for instance) that fit the bill perfectly.
Librarians also have their own portable bookshelf, where they store copies of only the most requested books. This way, they have to check the big library only when they don’t have a book readily available.
Lastly, librarians are "on call," coming online only when a request is received. After handling the request, they wait briefly for any additional queries and then go offline if none arrive.
This solves the issue of speed and scaling, but what about organizing the books? How do librarians know which books are assigned to them?
The answer is an algorithm called consistent hashing. It sounds complicated, but it’s actually quite intuitive.
This increases flexibility and speed, avoiding a total reshuffle when numbers change, and ensuring continuous availability for answering questions.
The remaining problem is handling unstructured vs. structured data (i.e. French vs. English books). Like we covered earlier, many systems couldn't store unstructured data, and those that could required a lot of extra work.
Snowflake’s approach to solve this issue consists of three steps:
- It allows the customer to store any kind of book, with no extra work on their side
- In the backlines, it implements “translators”, which translate and catalog these books for easy retrieval of information later on.
- The original copy of the book is also kept, in the odd chance that the translators made a mistake and it needs to be fixed.
This way, customers can easily store and retrieve any kind of data (structured and non structured), without any of the extra work required by previous systems.
How does the final user benefit from all these changes and improvements? Let’s see it in the next chapter.