

Limits of Past Solutions
Engineers soon realized that the quantity of data that they were dealing with was too big to fit into single servers.
And building ever more powerful servers was not a viable solution due to cost and available technology.
One of the solutions that they came up with was having two or more servers “joining forces”. This is called “distributed computing”, which is a fancy term to say “multiple servers working on the same task at once”.
The direct benefit of this approach is that it’s easy to scale: more data? Add more servers! Harder tasks? More servers!
Within distributed computing two architectures prevailed:
- Shared-disk/storage
- Shared-nothing
Back to the library metaphor:
Shared storage architecture
In the shared storage architecture, there is just a single, huge library building where many librarians (servers) work. Librarians have access to all parts of the library, and the books are stored and organized in such a way that books cannot be lost or misplaced.
It’s a very simple system. But it suffers from a major drawback: a moderate number of customers asking for books at the same time is enough to slow librarians down.
Imagine librarians running up and down, bumping into each other, trying to keep up with the requests. Adding more librarians won’t fix the issue as the traffic will only get worse.

Shared nothing architecture
The shared nothing architecture came as an answer to the librarian rush hour. In this architecture, each librarian has their own portable bookshelf, which contains just a small subset of books, shared with nobody else. This way, they can answer questions faster without bumping into each other.
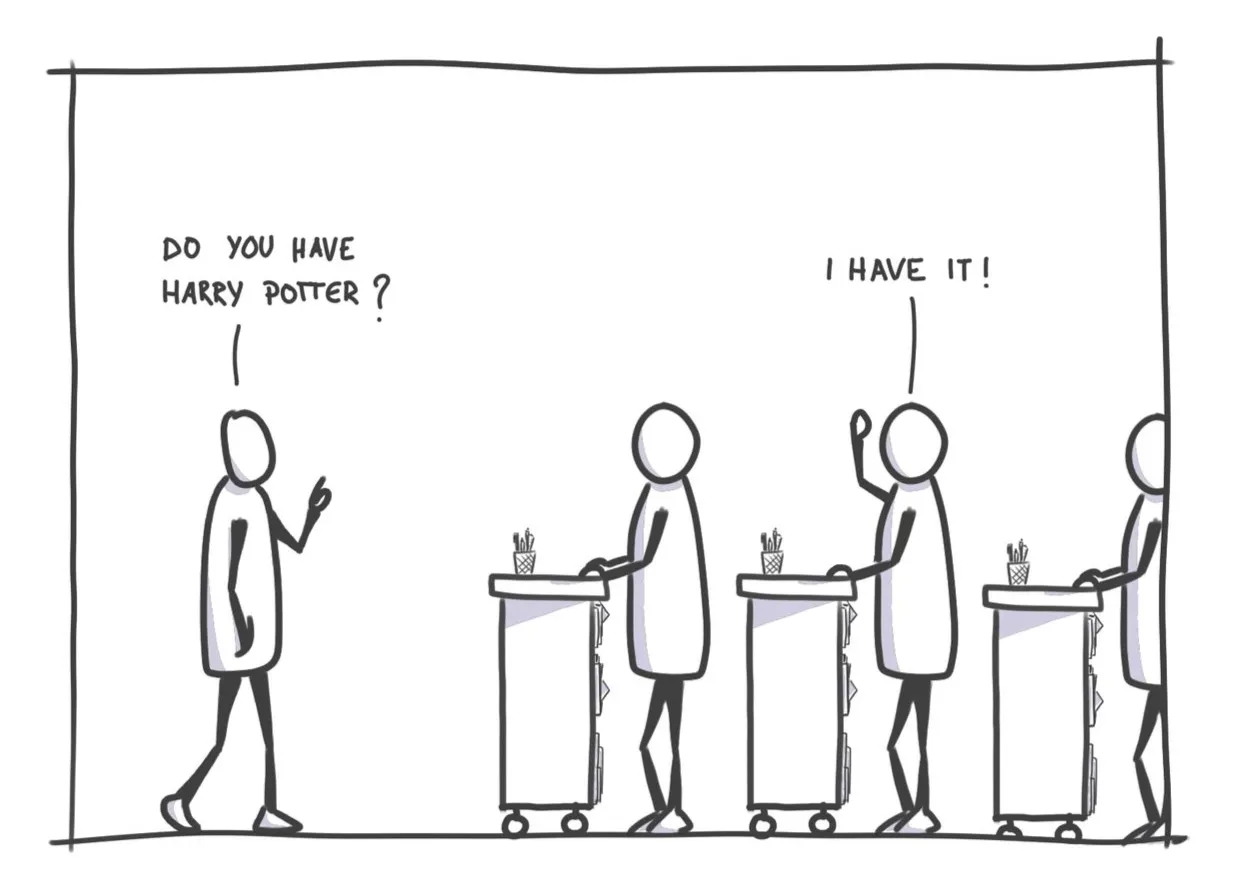
This system has drawbacks of its own:
- If the number of librarians changes, it causes problems. Books are organized by strict rules, so any change means starting over. During this time, librarians can't help customers, and the library has to close.
- While this system is able to answer simple questions very quickly, it can struggle with complex ones.

Finally, it is difficult to use resources efficiently when scaling. If we need to store many books, we need to hire many librarians (remember each of them comes with their own portable bookshelf). But during slow hours, most librarians would have nothing to do.
Additional Challenges
A common issue between the two architectures lies in what type of data can be stored. Traditional systems could only work with structured data.
Going back to our example, it’s as if our fictional library could only store books that are written in English.

Other systems were created that could store and analyze more heterogeneous, non structured data; in tech talk we call this topic “noSQL”.

Tech note
For example, solutions like Hive, Presto, Impala and Stinger provide a SQL interface on top of Hadoop/HDFS, making it possible to query and manage unstructured data.
Nonetheless, they still came with a lot of extra work, either for the maintainer or the user. Oftentimes, both.

On top of that, these alternatives also suffered from the very same problems described above, which reinforced the need to come up with a different approach.



Limits of Past Solutions
Engineers soon realized that the quantity of data that they were dealing with was too big to fit into single servers.
And building ever more powerful servers was not a viable solution due to cost and available technology.
One of the solutions that they came up with was having two or more servers “joining forces”. This is called “distributed computing”, which is a fancy term to say “multiple servers working on the same task at once”.
The direct benefit of this approach is that it’s easy to scale: more data? Add more servers! Harder tasks? More servers!
Within distributed computing two architectures prevailed:
- Shared-disk/storage
- Shared-nothing
Back to the library metaphor:
Shared storage architecture
In the shared storage architecture, there is just a single, huge library building where many librarians (servers) work. Librarians have access to all parts of the library, and the books are stored and organized in such a way that books cannot be lost or misplaced.
It’s a very simple system. But it suffers from a major drawback: a moderate number of customers asking for books at the same time is enough to slow librarians down.
Imagine librarians running up and down, bumping into each other, trying to keep up with the requests. Adding more librarians won’t fix the issue as the traffic will only get worse.
Shared nothing architecture
The shared nothing architecture came as an answer to the librarian rush hour. In this architecture, each librarian has their own portable bookshelf, which contains just a small subset of books, shared with nobody else. This way, they can answer questions faster without bumping into each other.
This system has drawbacks of its own:
- If the number of librarians changes, it causes problems. Books are organized by strict rules, so any change means starting over. During this time, librarians can't help customers, and the library has to close.
- While this system is able to answer simple questions very quickly, it can struggle with complex ones.
Finally, it is difficult to use resources efficiently when scaling. If we need to store many books, we need to hire many librarians (remember each of them comes with their own portable bookshelf). But during slow hours, most librarians would have nothing to do.
Additional Challenges
A common issue between the two architectures lies in what type of data can be stored. Traditional systems could only work with structured data.
Going back to our example, it’s as if our fictional library could only store books that are written in English.
Other systems were created that could store and analyze more heterogeneous, non structured data; in tech talk we call this topic “noSQL”.
Tech note
For example, solutions like Hive, Presto, Impala and Stinger provide a SQL interface on top of Hadoop/HDFS, making it possible to query and manage unstructured data.
Nonetheless, they still came with a lot of extra work, either for the maintainer or the user. Oftentimes, both.
On top of that, these alternatives also suffered from the very same problems described above, which reinforced the need to come up with a different approach.

Chapters

Chapters
How Snowflake Works: Intro
Understanding Data Warehousing

Limits of Past Solutions
How It Revolutionizes Data Warehousing?
How It Benefit Users: Wrapping Up
Cortex AI
New
What is Cortex AI?
The Case for AI in the Data Warehouse
An Overview of Cortex AI
LLM Functions
Snowflake Copilot
Limits of Past Solutions
Engineers soon realized that the quantity of data that they were dealing with was too big to fit into single servers.
And building ever more powerful servers was not a viable solution due to cost and available technology.
One of the solutions that they came up with was having two or more servers “joining forces”. This is called “distributed computing”, which is a fancy term to say “multiple servers working on the same task at once”.
The direct benefit of this approach is that it’s easy to scale: more data? Add more servers! Harder tasks? More servers!
Within distributed computing two architectures prevailed:
- Shared-disk/storage
- Shared-nothing
Back to the library metaphor:
Shared storage architecture
In the shared storage architecture, there is just a single, huge library building where many librarians (servers) work. Librarians have access to all parts of the library, and the books are stored and organized in such a way that books cannot be lost or misplaced.
It’s a very simple system. But it suffers from a major drawback: a moderate number of customers asking for books at the same time is enough to slow librarians down.
Imagine librarians running up and down, bumping into each other, trying to keep up with the requests. Adding more librarians won’t fix the issue as the traffic will only get worse.
Shared nothing architecture
The shared nothing architecture came as an answer to the librarian rush hour. In this architecture, each librarian has their own portable bookshelf, which contains just a small subset of books, shared with nobody else. This way, they can answer questions faster without bumping into each other.
This system has drawbacks of its own:
- If the number of librarians changes, it causes problems. Books are organized by strict rules, so any change means starting over. During this time, librarians can't help customers, and the library has to close.
- While this system is able to answer simple questions very quickly, it can struggle with complex ones.
Finally, it is difficult to use resources efficiently when scaling. If we need to store many books, we need to hire many librarians (remember each of them comes with their own portable bookshelf). But during slow hours, most librarians would have nothing to do.
Additional Challenges
A common issue between the two architectures lies in what type of data can be stored. Traditional systems could only work with structured data.
Going back to our example, it’s as if our fictional library could only store books that are written in English.
Other systems were created that could store and analyze more heterogeneous, non structured data; in tech talk we call this topic “noSQL”.
Tech note
For example, solutions like Hive, Presto, Impala and Stinger provide a SQL interface on top of Hadoop/HDFS, making it possible to query and manage unstructured data.
Nonetheless, they still came with a lot of extra work, either for the maintainer or the user. Oftentimes, both.
On top of that, these alternatives also suffered from the very same problems described above, which reinforced the need to come up with a different approach.